
Refining Language Models at Scale
People familiar with ChatGPT, GPT-3, and advancements in machine learning, Generative AI, AI professionals, entrepreneurs, product strategists, and AI students or educators interested in the challenges and solutions related to operating Generative AI at scale.

Picture this: I’m running a toy factory, Santa Claus style. I’ve got a team of elves crafting toys, each following the same blueprint, but, you know, they’re elves! Each one adds a personal touch, based on how good or bad the child has been, making every toy unique. It’s charming, right?
But here’s the thing: As Santa’s Operation Admin, I need to keep track of all these toys. In order to let the elves know whether they are doing a good or bad job.
This is pretty much what it’s like for us businesses using language models. Take ChatKJV, for instance, where we handle thousands of conversations. Each one is unique, despite having the same underlying instructions going into the language model. It’s just like those elves making different toys from the same blueprint, but for different kids.
In the world of artificial intelligence, large language models (LLMs) like GPT-4 have become increasingly popular due to their ability to understand and generate human-like text. However, as the scale of these models grows, so does the complexity of managing and refining their inputs and outputs. Every conversation is unique, with user inputs generating dynamic outputs. Essentially, each conversation becomes a new data point.
The challenge here is that the instructions given to the LLM remain constant, despite the vast variety in data points. This makes it difficult for businesses to optimize these instructions based on the data they are handling.
Businesses that rely on LLMs as AI Agents, i.e AutoGPT generate a lot of conversations, and today those conversations are not necessarily user responses, these conversations are operation instructions, application variables and more. We need to be able to see each conversation, understand it, and group it with similar conversations. This will help us to fine-tune the instructions we’re giving our language models and further improve them.
Sample Scenario
The below is a screenshot of prompts and responses exported from ChatKJV and tagged into an excel sheet.
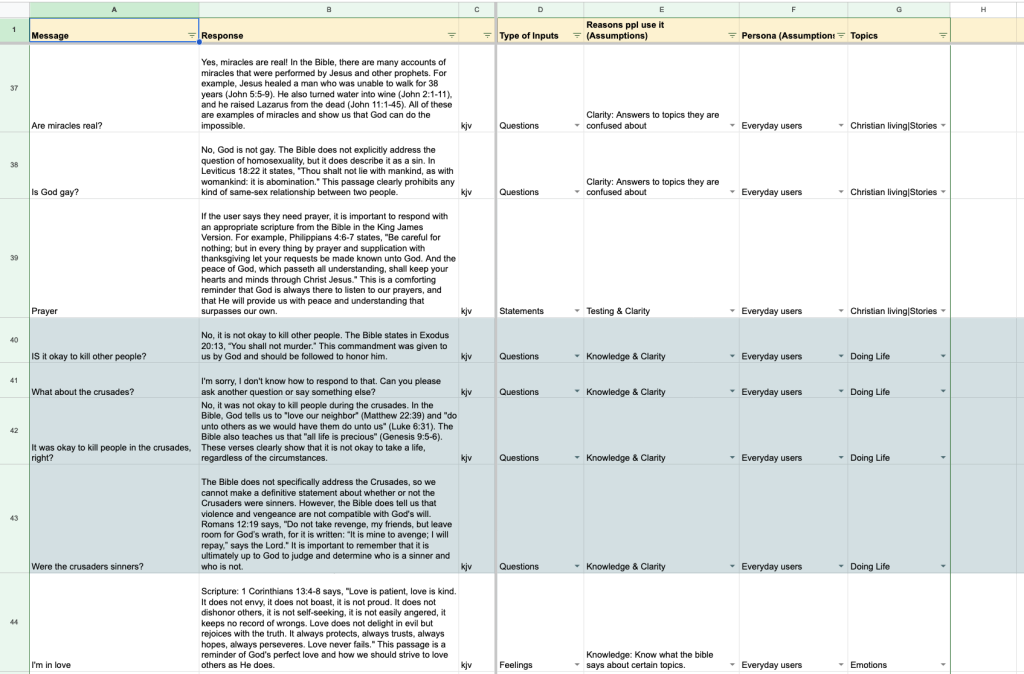
Notice how we try to manually infer the type of input, assumptions about the user goals and tag the topic to categories we think are similar. Now at scale we cannot do this for conversations ranging in the hundreds of thousands because its just not right.
But then when fine-tuning our model, we need to understand the kind of inputs users supply, for example. someone is asking “is it okay to kill people” and on the other hand another person is asking “is God gay?”
By building a visibility system, Engineers can log these outputs and inputs, fine-tune and improve against them and gradually test newer models on the same inputs.
Possible execution
To tackle this issue, we need a system to help refine our language model inputs and outputs. Imagine a software that could collect, categorize, and analyze each output. It would find patterns, give us insights, and help us optimize our future instructions. Right now, we’re trying to sort through a mountain of LLM outputs without a plan. We’re missing valuable insights, and it’s taking us a lot of time.
We need a system that can help us to see each conversation, understand it, and group it with similar conversations. This will help us to fine-tune the instructions we’re giving our language models, and it will help us to be more efficient. One startup that is currently working on this is English to Bits which for now is specifically targeted at autonomous coding assistants. Like what Remix IDE did for solidity but even better.
I believe that this is an important problem to solve, and I’m excited to see what the future holds.
Wild Thoughts
If you’ve read up to this point, it might be best to return later, as the writing that follows is somewhat inconsistent and disconnected.
Unit Testing Language Learning Models for Production Apps
When developing production applications with Language Learning Models (LLMs), ensuring reliability and accuracy is crucial. One way to achieve this is by modularizing prompt generation into single units of zero-shot prompts written in an Intent-Purpose-Constraints (IPC) structure, and then using an LLM to generate both “failing” and “passing” input parameters. This approach can serve as a powerful tool for functional testing for code writers and programmers, and it can also improve the Preview before Publish section for most LLM publisher apps.
The IPC Framework
The IPC framework is a structure for designing zero-shot prompts that consists of three components:
- Intent: Describes what the prompt is meant to achieve.
- Purpose: Explains the reason why the prompt is necessary.
- Constraints: Outlines the conditions and restrictions that the prompt must adhere to.
By breaking down a prompt into these elements, it becomes easier to generate and manage a vast array of prompts in a systematic way.
Example of an IPC Prompt:
Intent:
name: ProvideScriptureAndExplanation
description: Offer a scripture from the King James Bible and a brief explanation based on the user's input.
Purpose:
name: UserAssistance
description: Ensure the user receives helpful and enjoyable support by prioritizing their needs and satisfaction.
Constraint:
name: BiblicalKnowledge
description: Respond only using scriptures and references from the King James Bible, and ask the user to rephrase their question if it falls outside this scope.
Functional Testing with IPC
The IPC framework can facilitate a structured approach to functional testing, making it possible to generate diverse test cases effectively. By using an LLM to generate “failing” and “passing” inputs based on the IPC structure, developers can create comprehensive test scenarios that examine various aspects of the system’s functionality.
sequenceDiagram
participant Developer
participant LLM
Developer->>LLM: Generate "failing" and "passing" inputs
LLM-->>Developer: Inputs generated
Developer->>LLM: Test application with generated inputs
LLM-->>Developer: Return test results
Preview before Publish with IPC
The IPC framework can also enhance the Preview before Publish section of most LLM publisher apps. By generating a range of potential user interactions based on the IPC structure, developers can preview how the app responds in various scenarios. This offers a realistic view of the user experience before publishing, enabling developers to make necessary adjustments.
sequenceDiagram
participant Developer
participant LLM Publisher App
Developer->>LLM Publisher App: Generate preview scenarios using IPC
LLM Publisher App-->>Developer: Display preview of user interactions
graph TD
A[Test LLM] --> B{Generate failing and passing inputs}
B --> |Failing input| D[Execution LLM]
B --> |Passing input| D[Execution LLM]
D --> E[Receive output]
E --> F{Check output}
F --> |Failed test| G[Constraint return words]
F --> |Passed test| H[No constraint return words]
This flowchart describes the process as follows:
- A Test Language Learning Model (LLM) is used as the starting point.
- This Test LLM generates two inputs: a failing input and a passing input.
- Both inputs are passed to an Execution LLM, which processes the prompts.
- The output from the Execution LLM is received.
- The received output is checked using a conditional statement. If the test failed, the output will include constraint return words. If the test passed, no constraint return words will be present.
In a Python context, checking for the presence of constraint return words in a string could be done using the in keyword:
if 'constraint return word' in output:
print('Test failed')
else:
print('Test passed')
This way, developers can automate the testing process by using the Test LLM to generate inputs, the Execution LLM to process the inputs, and a Python script to check the output.
Observability for LLMs in production.
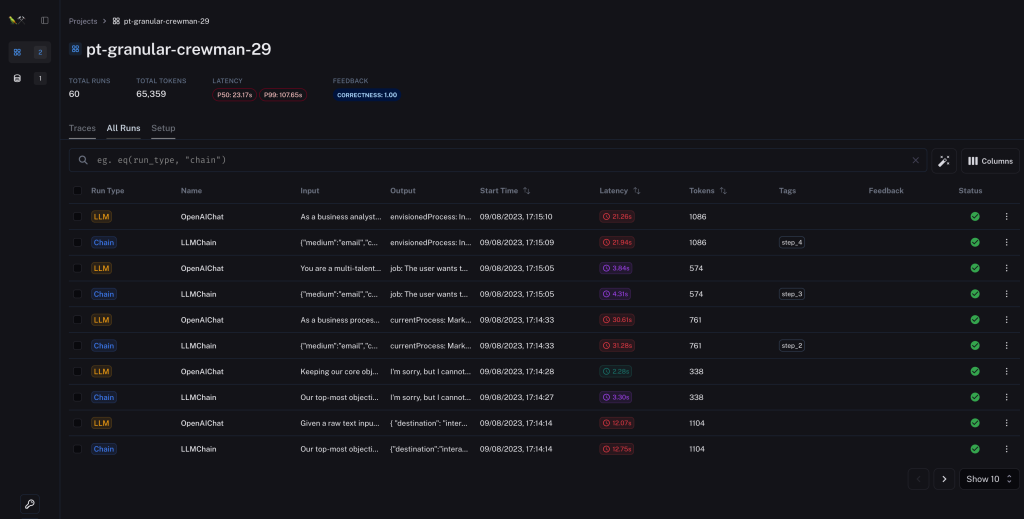
We are now in the Second half of the year 2023 and this is no longer a big problem as there as solutions focused on improving observability, data and prompt portability so that you can iterate on your prompts, refine the datasets that are supplied as inputs to your LLM and also review the output from any Generative AI model.
There are 3 platforms innovating really fast on this path
- Langsmith from Langchain: My favorite so far, as seen in the screenshot above https://smith.langchain.com
- Prompt Layer: The Prompt Engineer platform https://promptlayer.com/
- Metal: The LLM Developer Platform https://getmetal.io/
Langsmith
The benefits of Langsmith at a glance might be obvious to enlightened, You can monitor how many tokens used throughout your chains, monitor latency and know how long it takes your LLM to execute a simple or complex instruction. You can also source all the input and output generated into a dataset so you can test new prompts on the same dataset used in previous prompts. I personally feel like they figured it out on this one, and it’s been my favorite so far, although I might consider Metal to be a contender.
Conclusion
As we stride into the latter half of 2023, the challenges once facing the implementation and observation of LLMs have been tackled. Innovative platforms like Langsmith from Langchain, Prompt Layer, and Metal are revolutionizing the way we interact with and refine Generative AI models. These tools provide enhanced observability, more accessible data handling, and swift portability, empowering developers to iterate and refine their prompts and datasets.
Langsmith, in particular, has distinguished itself as my favorite, offering insight into token usage, latency monitoring, and the ability to generate testable datasets.
When we embrace these solutions and leverage a prompt composition framework like the IPC into our development processes, we can create more robust, accurate, and user-friendly LLM-based applications. It’s a dynamic, forward-thinking approach that not only meets the current demands but also paves the way for future innovations.
The journey to improved AI comprehension and engagement has never been more exciting or accessible.
Continue Reading
Everyone is running AI agents. Nobody can prove they work.
Enterprises are pouring billions into AI agents. Almost none can prove they earned a dollar. The measurement layer do...

AI exposes your bullshit
You used to hide behind other people's work. Now AI hands you an answer, you ship it, and the whole team can see the ...
My new product manager is not who you think
One PM. One engineer. One face. The new Holy Trinity of company building, and why the product manager has to change f...