
Mechanisms for building Problem Solving General Artificial Intelligence with LLMs
This article is a 🌱 Seedling, which means it’s still Work in progress and published in it’s raw form.
More on Seedlings
Understanding how to leverage AI for problem-solving in the same manner as humans isn’t straightforward. Given that there has been a lot of research done in this field, there are four research papers that delve into the nuances of this process, with very interesting approaches.
They explore how we can fine-tune AI models to make them capable of reasoning and problem-solving, even in a business context where tasks need to be prioritized. Let’s get into them, shall we
MRKL (“pronounced Miracle”)
You’re going to love this one, it’s actually named after yours truly! ☺️ So, let’s dive right into the MRKL framework. I’m going to make things easy for you and explain it using an example from something you’re already familiar with.
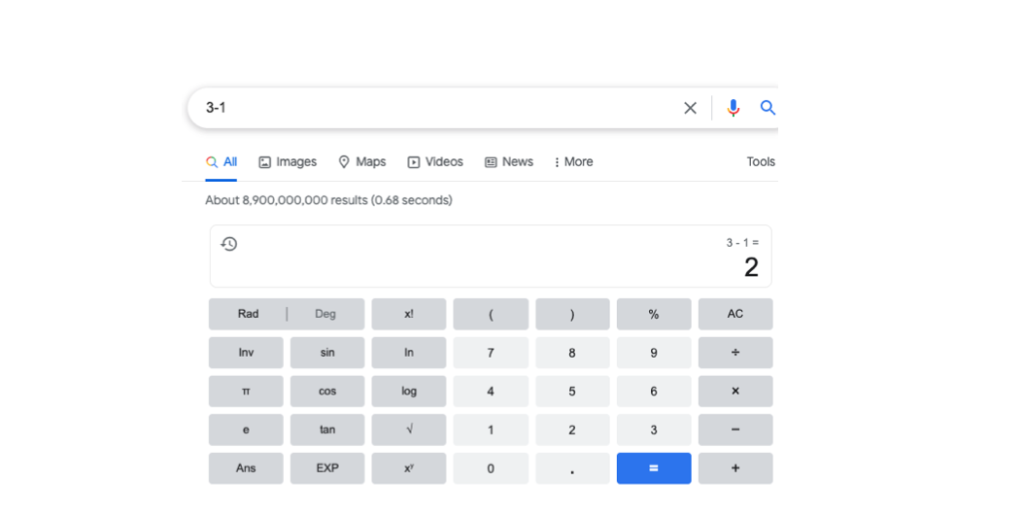
This example is straight from the MRKL paper and it showcases the response to a simple question asked on Google.
The First is a simple question “3 + 1” that google can easily answer with their machine learning implementation
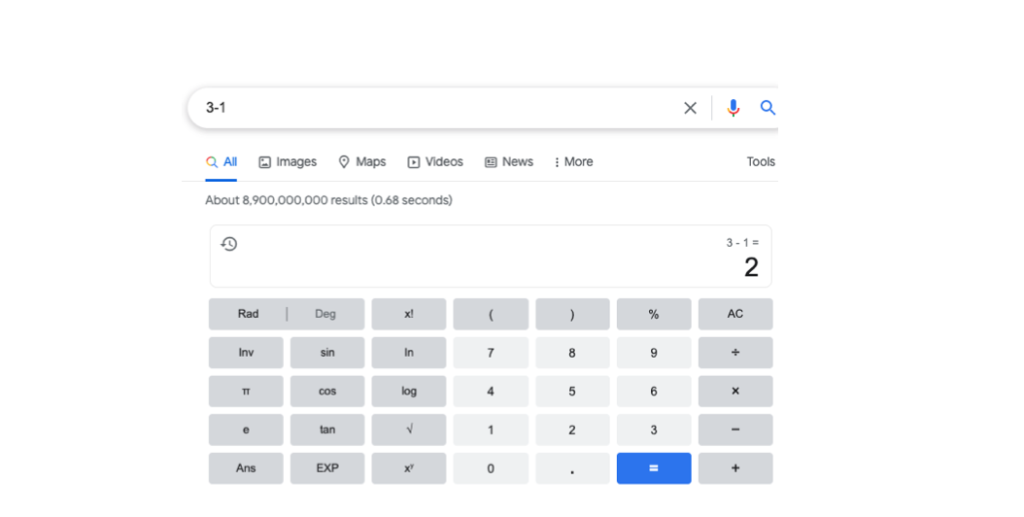
The second is the same question but in natural language
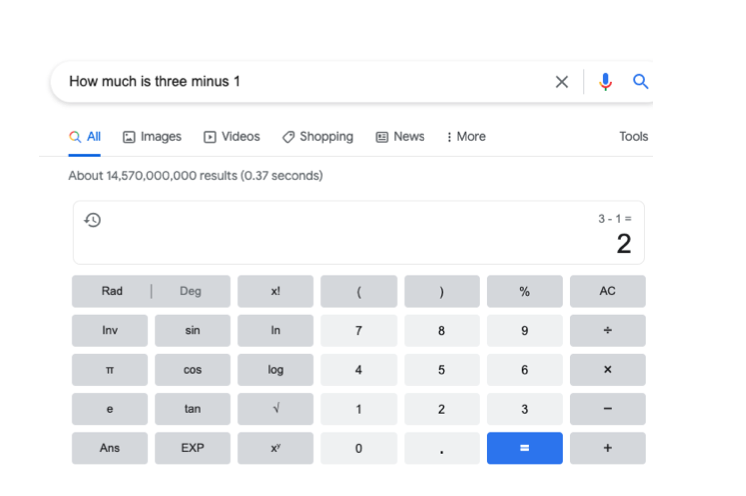
Finally the last image here is one that asks a similar arithmetic based question but with language.
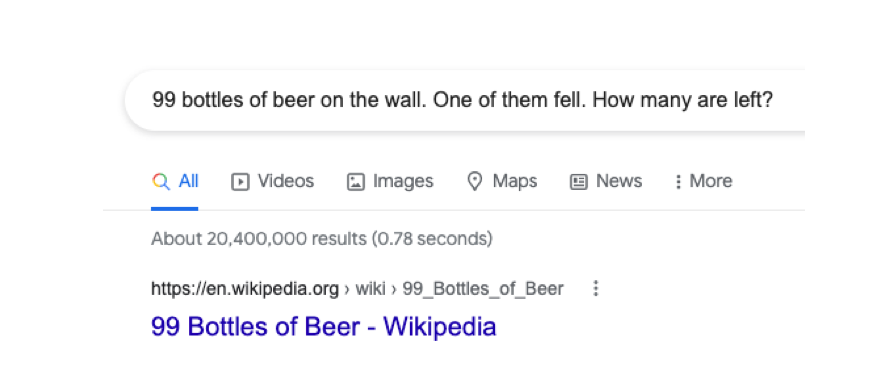
Normally this is easy for a human to comprehend, as we can understand that bottle is an entity and if we place 99 of it on a wall, and one falls, we would have 98 left.
But we should approach even this task with sober expectations. As anyone knows from elementary school, it’s harder to teach children to solve verbal math problems than to solve explicitly stated math problems. It’s harder for adults too, and it’s no different for the computer.
This is where Miracle comes in “I got tired of calling it MRKL” — It uses a Router and an Expert to handle incoming communication, which makes it really extendable.
Router: The router does one thing: Understand if there is a task that can be performed from an input and route it to the right resource to handle it.
It truly is Miraculous, So as long as you can reinforce it with enough resources and experts, it can find someone to do the job. I started with MRKL, because it’s a fundamental aspect that drives execution when utilizing reasoning Language models.
ReAct Paper Overview
The next paper we look at is the ReAct.
A unique feature of human intelligence is the ability to seamlessly combine task-oriented actions with verbal reasoning (or inner speech, Alderson-Day & Fernyhough, 2015), which has been theorized to play an important role in human cognition for enabling self-regulation or strategization.
React is not entirely action oriented like the MRKL system, however it creates a really good buffer that generates both reasoning traces and task-specific actions in an interleaved manner. This means that we can watch and learn how a Language Model thinks through the execution of a task.
While that would seem like a lot of verbose data, it’s going to be relevant for the next papers I will share. The Tree of Thought and the OpenAI Let’s Verify Step by Step
The MRKL framework emphasises on a router, like a Traffic Controller who decides what path a task or information given to it will go. while ReAct, gives us a way to REASON and see what our Language model is thinking, It’s like having a driver whose Traffic indicator is always on and they are constantly telling you when they’re braking, taking a left turn or a right turn, or even as verbose as having a visual of their speedometer on top of the car to tell you what gear and miles per second, they are driving at.
These two papers will lay the foundation for the the Tree of Thought and the Verify Step by Step which are more recent and newer breakthroughs.
Tree of Thought (ToT)
In a nutshell, ToT like a Tree is a Language Model that has so many branches of reasoning that we can see, and the ToT model will pick the one that is closest to the input sent in. so think ReAct but like an apple tree with branches. I did a Twitter thread on the ToT model
The new OpenAI paper isn’t far from these because it suggest that you can improve the ability of a language model to solve problems if you reward it for how well it reasons instead of the final outcome.
It’s like teaching a child how to play the piano, and you reward the first child for using the right fingering technique to play a C major scale, and you don’t reward the second child, even though they were able to play the scale at a better speed and accuracy, they used the wrong fingering.
I will stop here for now, and revert back to this later, when I have more information
References and Further Reading
OpenAI
Deliberate Problem Solving with Large Language Models
MRKL Systems, A modular, neuro-symbolic architecture
Ehud Karpas, Omri Abend, & Co
Prompting ChatGPT for Multimodal Reasoning and Action
Shunyu Yao, Jeffrey Zhao & Co
Continue Reading
Everyone is running AI agents. Nobody can prove they work.
Enterprises are pouring billions into AI agents. Almost none can prove they earned a dollar. The measurement layer do...

AI exposes your bullshit
You used to hide behind other people's work. Now AI hands you an answer, you ship it, and the whole team can see the ...
My new product manager is not who you think
One PM. One engineer. One face. The new Holy Trinity of company building, and why the product manager has to change f...